En partenariat avec l’association Apéro Web Lyon, Peaks a accueilli ce jeudi 23 février, dans ses locaux lyonnais, un meet-up en deux temps. Les sujets : intégration continue et atomic design.
Découvrez le premier talk sur l’intégration continue, présenté par Gabrielle, développeuse Full Stack chez Peaks.
Pourquoi ne pratiquez-vous pas l’intégration continue ?
L’intégration, qu’est-ce que c’est ?
L’intégration, c’est l’incorporation d’une modification du code dans la branche principale. Dans le process d’intégration, cela implique la résolution des conflits (GIT ou fonctionnels) afin d’obtenir une version correcte du programme. Typiquement, un merge sur la branche « main » ou « develop ».
Le standard : feature branching
Implémentation d’une fonctionnalité en Feature Branching
Voici les process mis en place dans la majorité des entreprises :
- Récupération de la dernière version à jour du code (git pull main)
- Développement de la fonctionnalité, rédaction des tests et de la documentation
- Commit et push sur une branche exclusive à la fonctionnalité
- Création d’une Pull Request
- D’autres développeurs font une relecture du code
- Pendant ce temps, on commence à travailler sur une autre fonctionnalité
- En cas de retours, on retravaille le code et on demande à nouveau une relecture
- En cas d’acceptation, on merge.
Problème 1 : la résolution des conflits
D’abord, le premier problème dans ce processus est la résolution des conflits.
Le temps d’attente entre la création de la pull request et le moment où elle est validée est trop long. En effet, plus la Feature Branch reste vivante longtemps, plus de développements auront été intégrés entre temps et plus il y aura de conflits à résoudre pour merge la Feature Branch.
- Perte de temps, surtout avec le contexte switching
- Conflits parfois difficiles à identifier (exemple : appel d’une fonction qui a été renommée)
- (Opinion) On est mauvais
La solution : Git rebase.
La politique du Changement Minimum
Afin de résoudre ces conflits, certaines équipes adoptent une politique du « changement minimum » : une PR ne doit contenir aucune modification pas strictement nécessaire à l’implémentation de la fonctionnalité.
Tout autre modification (amélioration de la DX, refactoring, drive-by bug fixing…) doit être l’objet d’une PR séparée, ou même d’un ticket JIRA à planifier.
Le problème : le processus pour merge une PR étant assez souvent lourd et lent, le développeur n’est pas encouragé à prendre ces initiatives, et le travail nécessaire n’est donc pas fait.
Cela est exacerbé dans le cas d’un ticket JIRA, en y ajoutant aussi de la négociation avec le Product Owner qui n’est pas capable d’estimer la priorité.
Où est-ce que j’ai mis mon commit ?
Parfois, le développement d’une fonctionnalité dépend du développement d’une autre fonctionnalité en cours de relecture.
Classiquement, cela implique de commencer le développement de la Feature Branch en cours de relecture au lieu de la branche principale.
Hors, toutes modifications suite à la relecture de la première Feature Branch doivent ensuite être rapatriées sur les branches enfant.
En conséquence, la possibilité d’erreur est renforcée et les modifications ajoutent un poids mental.
Problème 2 : Context Switching
Lorsque l’on attaque la relecture, on commence également le travail sur une autre fonctionnalité.
Cependant, le travail sur la première fonctionnalité n’est pas fini.
–> Contexte Switching
–> Perte de productivité
L’épitome du problème : la grosse branche de migration
- Dure toujours trop longtemps
- Bloque le travail de tous les jours car « il faudra refaire quand la branche sera merge »
- Est toujours en retard car on ne peut pas estimer le temps que prendra l’intégration.
- Implique un certain nombre de régressions.
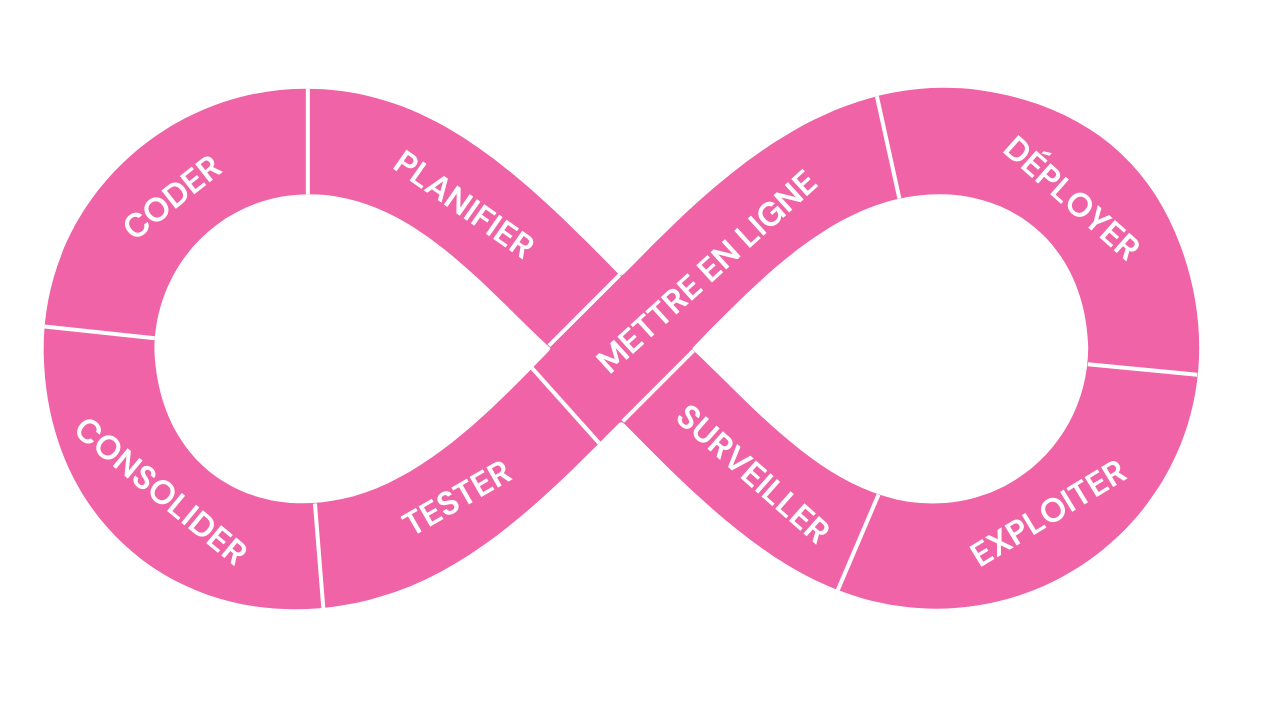
L’intégration continue
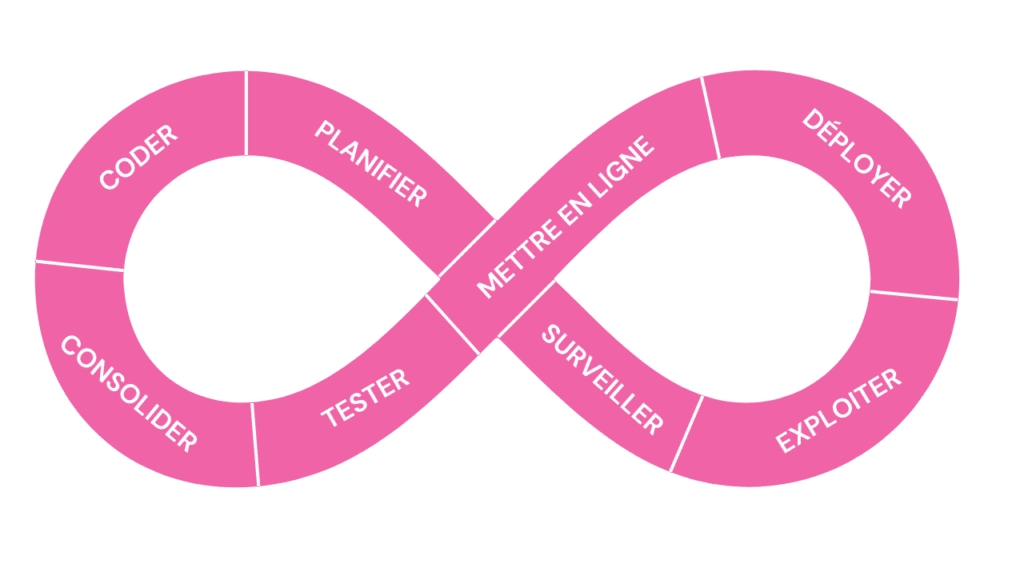
L’intégration continue, c’est que le travail que le développeur fait dans la journée doit être merge sur main dans cette même journée (au moins une fois). Il y ait au moins un commit sur main chaque jour sur le travail de chaque développeur. Cela rentre dans la philosophie d’agilité : de faire les choses le plus souvent possible et de récupérer du feedback le plus tôt possible.
L’intégration continue a été popularisée par Kent Beck, très connu pour être à l’origine du TDD et l’un des signataires du manifeste agile. Dans les années 90, il a développé l’extreme programming.
Dans l’Extreme Programming, il y a des principes et des pratiques : le TDD et l’intégration continue.
L’intégration continue, comment cela fonctionne ?
Implémentation d’une fonctionnalité en Intégration Continue
- Récupération de la dernière version à jour du code (git pull main)
- Développement de la fonctionnalité, rédaction des tests
- On exécute les tests en local puis, au moins une fois par jour, commit et push sur la branche principale au lieu de faire une PR.
Prérequis de l’intégration continue
Lors de la livraison continue, c’est à dire que dès lorsque l’on fait un commit sur main, cela fait un déploiement et une livraison. Il faut alors :
- Un serveur de CI (Github Actions, Gitlab CI, …)
- Une exécution des tests en local de façon synchrone
- Une exécution des tests rapides (< à 10 minutes)
- Utiliser des Feature Flags
- Eviter les travaux massifs de fond : pas de migration massive d’un coup
- Corriger le plus vite possible si les tests ne passent pas sur la branche principale
Pratique complémentaire : Pair / Mob Programming
Une pratique assez essentielle dans l’intégration continue est le Pair Programming et le Mob Programming.
- Meilleure qualité que par relecture
- Processus synchrone
- Aspect humain
Les avantages de l’intégration continue
- La réduction des risques : il y a moins d’incertitudes car on met en ligne souvent et petit à petit.
- Amélioration de la productivité
- Simplicité : cette pratique libère l’esprit et de livrer des fonctionnalités.


